
The AI inference war: chips, billions of tokens per day, and the road to zero
How multiple startups are competing against tech giants by developing their own hardware/software stacks that enable faster inference at a cheaper price.

Hello everyone,
Hope you are having a great Tuesday!
If you are reading this article about AI, and don’t know what inference is, don’t worry, you are not alone. While I was doing research for this article, many people close to me asked me about what I was writing, and when I said inference, I encountered blank faces. If you aren’t either in the machine learning and artificial intelligence field, or in the software development space developing AI apps, you probably don’t know what inference is.
The definition that Cloudflare, an internet infrastructure company, provides in one of their articles is quite clear: “inference is the process that a trained machine learning model uses to draw conclusions from brand-new data”.
But let me simplify it even more.
If you’ve used ChatGPT by OpenAI, Claude by Anthropic, or even Gemini from Google, you’ve interacted with AI models.When you write and send a question via the chat of one of those platforms: the message is sent to the backend (server); the input (your question) is “fed” to the AI model; the AI model processes the question and generates text as an output; and the response is then sent to your browser/app (the client), in which the response is displayed. In other words, you sent the model “brand-new data”, and the “machine learning model” used the data to “draw conclusions”.
Now that we understand what inference is, we can ask ourselves about the companies that provide inference.
One could think that the creators of the most popular AI models themselves provide the inference, but that is not the case for OpenAI and Anthropic. These AI startups don’t have the infrastructure to provide the inference themselves; they created the AI models that you may use in their end product, or companies such as Notion use to provide an AI feature, but the processing power needed to train the AI models and provide inference is often in the power of one of the big tech companies such as Amazon Web Services, Google Cloud or Microsoft Azure.

As you may have guessed, training an AI model, and then providing inference is not a cheap or easy task. Both Open AI and Anthropic raised billions of dollars and entered in partnerships with some of the big tech companies to be able to train and provide inference for their cutting-edge models.


In the case of OpenAI, their exclusive cloud provider is Microsoft, who has invested in the company in 2019, 2021, and just recently participated in an $8.8 billion dollar round with other investors such as Nvidia and Thrive Capital. Earlier this year, the startup (I don’t know if i should continue calling it so) extended their partnership with Microsoft, and in their press release, we got information about the nature of their partnership, and one of the most important news, in my opinion, which is that they will remain the exclusive cloud provider of OpenAI.
In the case of Anthropic, their exclusive cloud provider is Amazon. After receiving an investment from Amazon of $4 billion in September 2023 and naming it as its primary cloud provider, the startup received an additional $4 billion investment in the last quarter of 2024. The latest news about the investment also provided readers with the fact that Anthropic will now, according to Amazon’s website, “use AWS Trainium to train and deploy its largest foundation models”, and according to Anthropic’s website, work “closely with Annapurna Labs at AWS on the development and optimization of future generations of Trainium accelerators”. If you don't know what AWS Trainium is, don’t worry, we will talk about it later. In the meantime, think of it as Amazon’s chip, optimized for AI training and inference.
As you may already guessed, as the AI models created by OpenAI and Anthropic are very valuable (we’re talking billions of dollars of investment), the companies decided to not make their models open-source (this means that no one other than them can know with precision how these models were created).
But luckily, other companies have been developing multiple different open-source models, and made them available to the public. At first, open-source models weren’t as good as OpenAI’s GPTs, but in the last year, with the appearance of Meta’s family of very capable advanced LLM models, and Mistral’s (a french company!) LLM models, the game has changed.
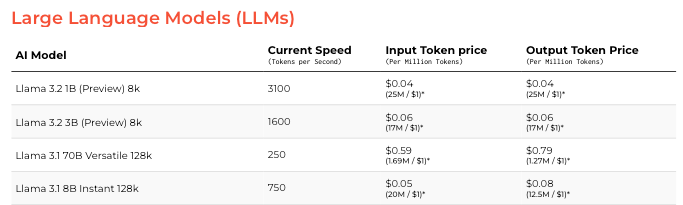
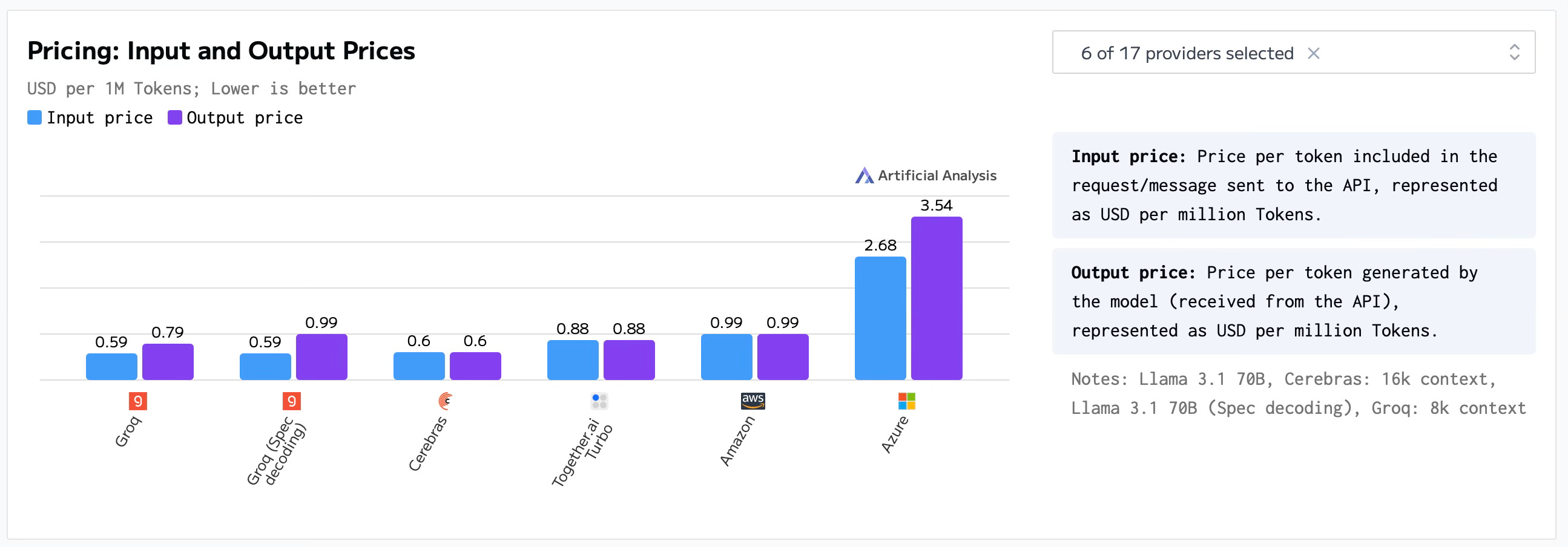
A positive consequence of the new open-source AI models, is the apparition of AI infrastructure companies such as Groq, Cerebras, and Together.ai. But, how are these companies able to compete with Amazon, Google, and Microsoft? We’ll get into specifics later, but in general terms, they provide faster response times and an incredibly lower cost per million tokens (definitions vary, but a token could be considered ~3 characters), thanks to their custom hardware and/or software stacks. Just as an example, 1 million input tokens and 1 million output tokens of OpenAI’s gpt-4o costs $2.50 and $10.00, while 1 million of either input or output tokens of Meta’s Llama 3.2 90B Vision, provided by Together.ai costs $1.20. To some, the difference may not seem significant, but imagine an app that uses 100s of millions of tokens per day.
Now that we have a general sense of the space, let’s talk about the incumbents (Microsoft, Amazon, and Google), the underdogs (Groq, Cerebras, and Together.ai), how they compare, and what the future may hold.
The incumbents
The big established tech companies that powered the tech revolution of the 21st century: Microsoft, Google, and Amazon.
With their multiple data-centers spreading around the world, their 100s of billions of dollars, and their seemingly top-tier teams, they could seem unbeatable to some.
But at the end of the day, despite their immense amount of resources, they all need to get GPUs from other providers, specifically Nvidia.
But as the three companies cannot rely on a single source for all their AI computing, they have started to develop their own AI chips: Microsoft developed Maia 100; Amazon developed AWS Inferentia and AWS Trainium; and Google developed Trillium.
All of these factors could scare away most startups -imagine your competition being Amazon, Google, Microsoft, and Nvidia-, but Groq, Together.ai, and Cerebras, apparently weren’t.
The underdogs
Groq
The AI inference startup, which recently (August 2024) raised $640 million in a Series D round at a $2.8 billion valuation, is gaining the spotlight as the king of AI inference.
But this is no accident.
The folks at Groq have developed their custom AI chip that apparently allows them to deliver, according to their website, “instant speed, unparalleled affordability, and energy efficiency at scale”. The AI chip, which they call LPU (Language Processing Unit), is different from the GPUs (Graphic Processing Unit) that most companies have been using, because it has been specifically designed for AI inference and language.

Their custom AI chip has enabled Groq to provide inference at a speed, and cost which is, for a developer like me, just astounding.
In an article by Groq called “What NVIDIA Didn’t Say”, the startup talks about the Nvidia’s Blackwell announcement, and what Nvidia’s CEO said and didn’t say. In essence, what Nvidia did was unveil their new “AI Superchip”; and what the folks at Groq basically said in the the article is that Nvidia’s CEO talked about a bigger chip, but not about “changing the underlying approach to running models” or “ how to improve performance or efficiency through redesigned system architecture”. In this article they appear to plant the flag stating their way, the “Groq LPU™ Inference Engine”, is the way. Their LPU was “architected from the ground up to run solutions like LLMs and other generative AI models with 10X better interactive performance and 10X better energy efficiency.”
So until now we know the basics of the startup, but what is really amazing is that they are not stopping here; they are already working on their next AI chip. Their next generation of silicon will be, according to PR Newswire’s article, “manufactured by Samsung on its SF4X process (4nm)”, and “is set to improve throughput, latency, power consumption, hardware footprint, and memory capacity”. If the current speeds and pricing is just magical, imagine what will happen when the silicon goes from 14 nm to 4nm.
One of the things that differentiates Groq, is that they apparently care about scalability. In a recent Youtube video, Jonathan Ross (Groq's CEO & Founder), said that they are careful when onboarding new clients, because they want to provide a fast service that stays fast. What I think Groq's CEO is referring to is the fact that a provider may show fast speeds in a benchmark, but one of the most important things is to always provide fast inference for clients.
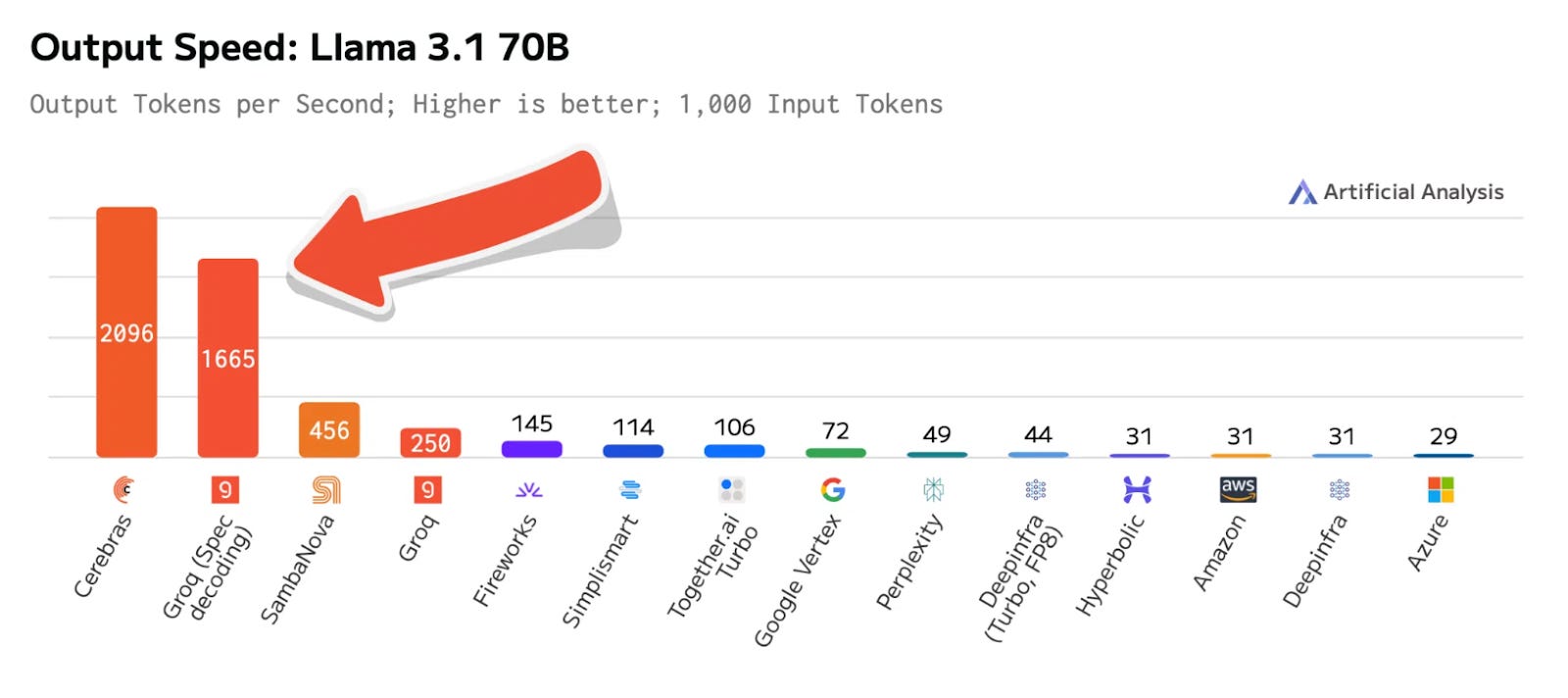
But Groq does not only appear to be about optimizing hardware, just recently they introduced LLama 3.1 70b Speculative Decoding on GroqCloud. According to their announcement, this new version of Llama “implements speculative decoding, a process that leverages a smaller and faster ‘draft model’ to generate tokens that are verified on the primary model”. And what is really interesting, is that their team achieved a “performance jump from 250 T/s to 1660 T/s” (T/s is tokens per second), on their current generation LPU architecture.
With regards to the use of Groq in data centers, in September 2024, Aramco Digital, a subsidiary of Saudi Aramco, announced a partnership with Groq to, according to Groq’s article, “build the largest AI inference data center in Saudi Arabia”. This data center “will leverage Groq ® LPU™ AI inference technology, advanced AI processors designed specifically for massive-scale inference workloads and delivering speed and efficiency.” This is huge news, not only for Groq as a company, but for developers from that region, as a highly capable data center focused on AI would mean better speeds (lower latency).
Cerebras
A pioneer in the AI semiconductor chip space. Since its foundation in 2015, the startup has developed AI chips for multiple industries such as Energy, Pharma, and others. Since then the startup raised multiple investment rounds, which pushed it to a valuation of over $4 billion. With all these years of experience in the AI space, Cerebras should have an advantage, and from what I have seen about the startup, it appears that it has.
All over their website I encountered words like “world’s fastest” and “instant responses” (we will later check the benchmarks to compare), but what really shocked me was their other claims:
LLama 3.1 70B uses ⅓ the power of on-prem GPUs, and runs 70x faster than GPU Clouds (which ones I would like to ask).
LLama 3.1 405B uses ⅓ the power of on-prem GPUs, and runs 75x faster than GPU Clouds.

Cereberas clearly appear to be competing on speed, and why shouldn’t they, considering the numbers they are doing. But other info from their website, clearly shows who they are competing with, and makes me really interested in the fact that the big tech companies are not even being named (just a mention of GPUs).

And how did Cerebras achieve this incredible speed?
Well, just as Groq, Cerebras developed its own AI chip, called WSE-3.

According to their website, “Cerebras’ third-generation wafer-scale engine (WSE-3) is the fastest AI processor on Earth”. This is a big claim, but apparently they back up it with the information shown in the table below.

According to them, one of the biggest advantages of their AI chip is that: it provides cluster-scale performance in a single chip; and the chip is easy to program and does not require typical dozens of hundreds of engineering hours.
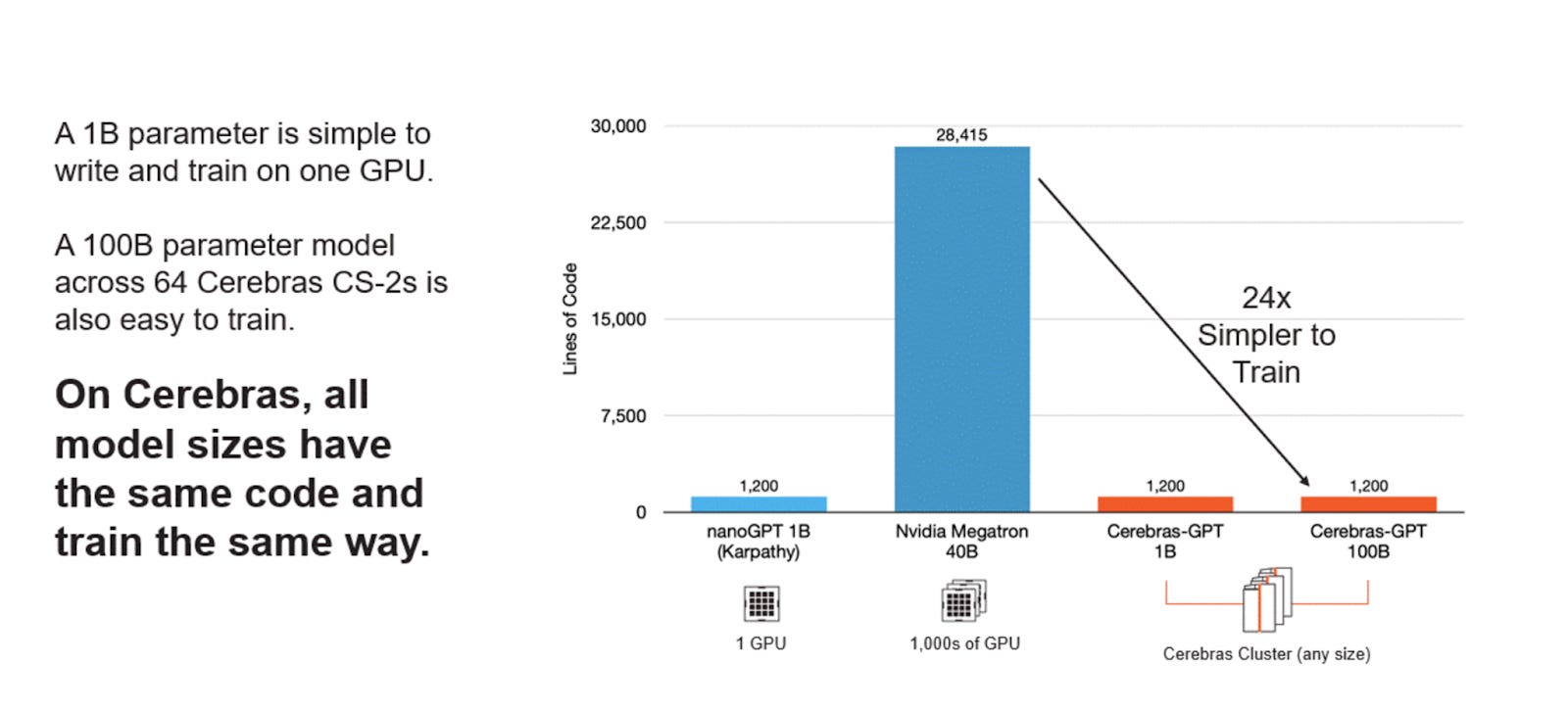
Apart from inference and AI chips, Cerebras built, with a company called G42, a supercomputer called Condor Galaxy. According to them, what's a game-changer about this supercomputer is how simple it is to write and train an AI model with the supercomputer instead of thousands of GPUs.
Together.ai
I included this company, because they act more as an infrastructure provider than the other two.
I don’t imagine Cerebras using Groq’s LPUs, or Groq using Cerebras AI Chips, but I can imagine Together.ai doing so.
Using Together “AI Acceleration Cloud”, one can train, fine-tune, and run inference on AI models. According to their website, they provide more that 200 generative AI models related to chat, language, embeddings, images, code, and reranking.
Together.ai seems to be an end to end solution.

In terms of speed and pricing they appear to be competitive (please refer to the benchmarks section of the article), but from an inference point what also makes them different -apart from the amount of models they provide-, are: the cost, the endpoint offers, and the possibility of VPC and on-premise deployments.

Benchmarks
The best way to end the article is by showing where we are at now in terms of benchmarks Llama 3.1 70B.
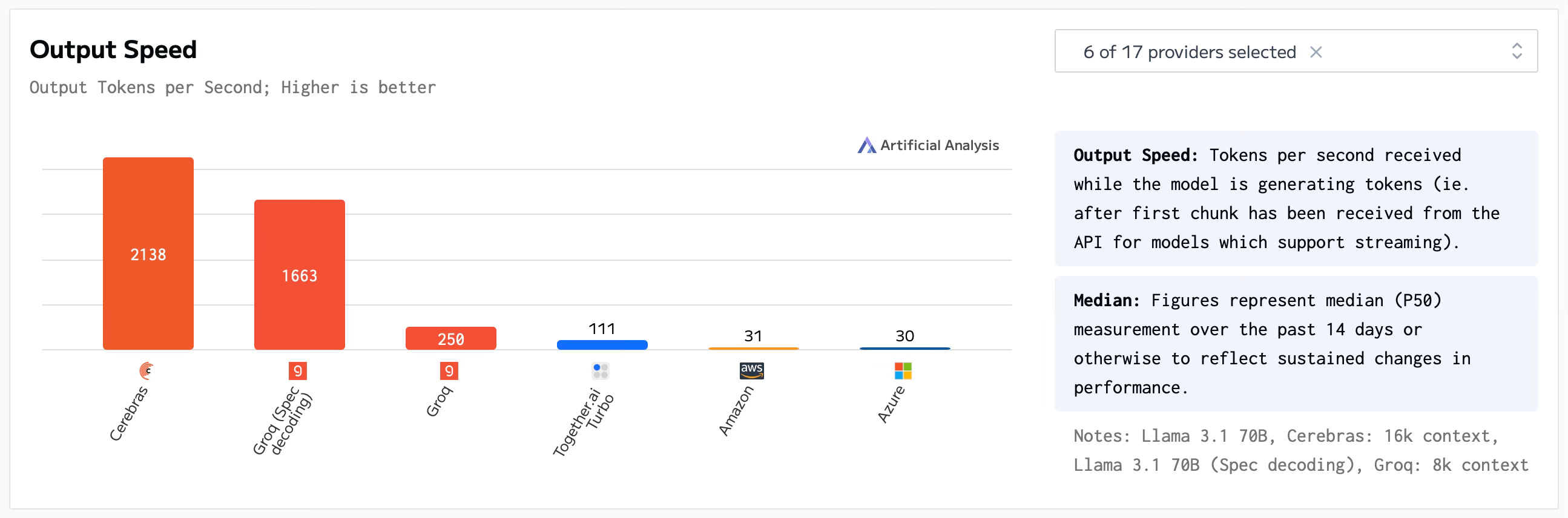
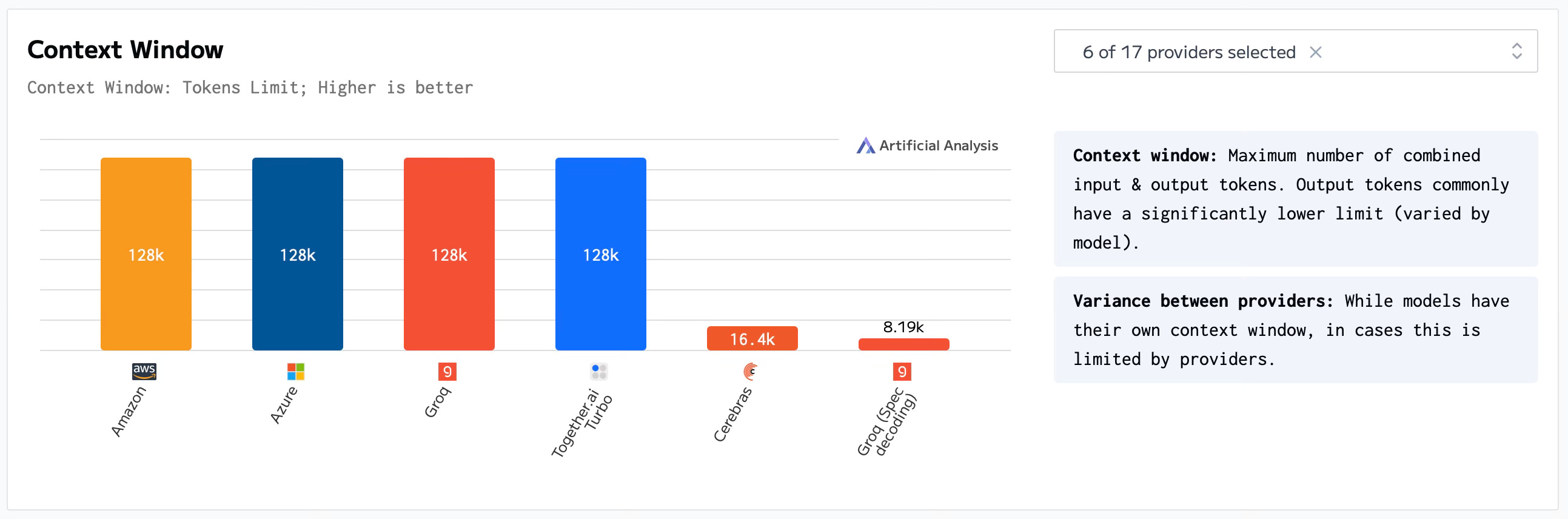
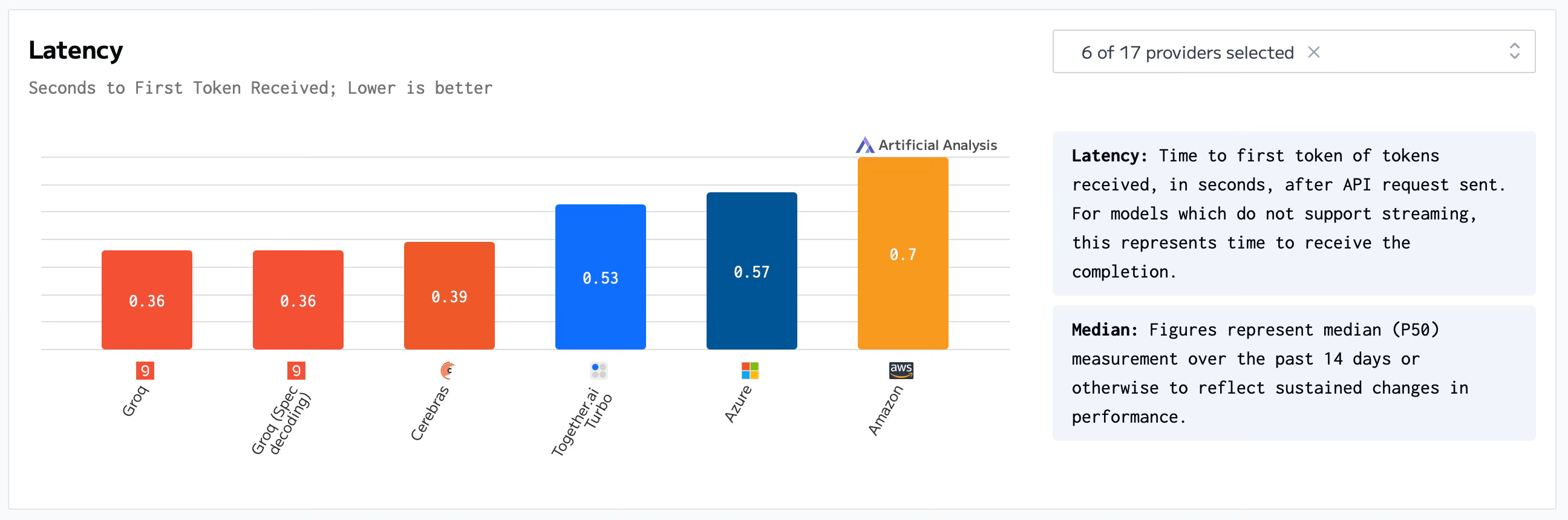
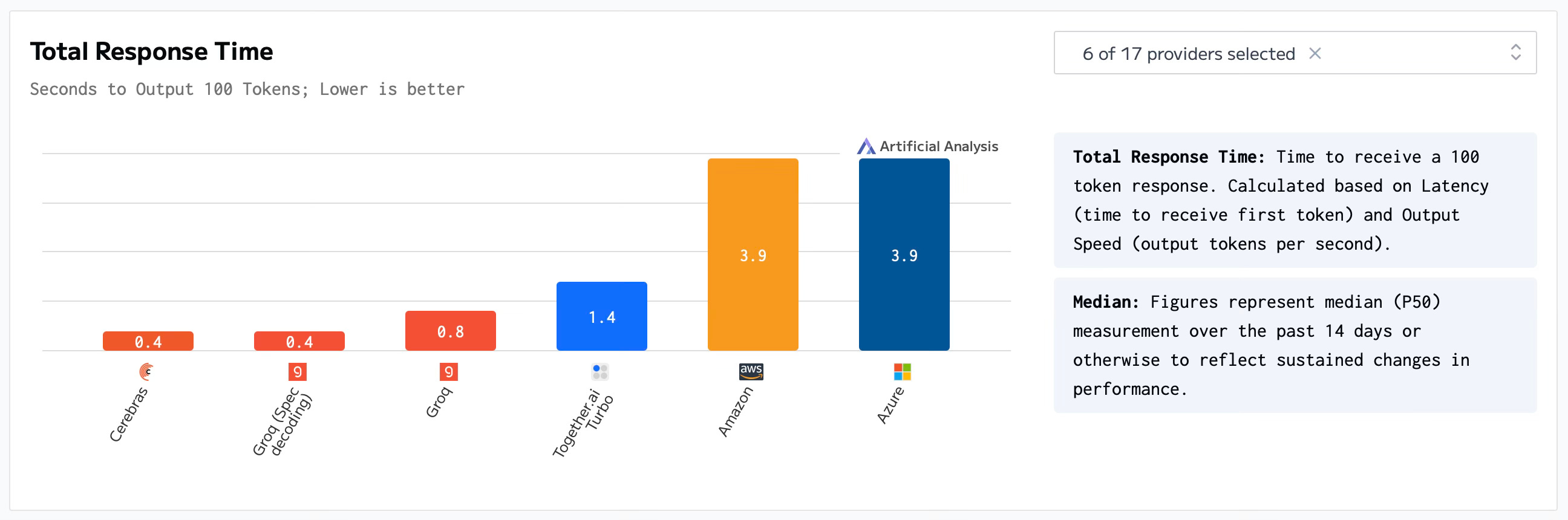
How the charts will look in 2025, we don’t know, but thanks to the innovative startups moving the needle forward, the future of AI Inference looks bright.
Author’s ending note
The world we deserve needs relentless techno-capitalists who theorize how to turn the impossible into possible and perform the necessary actions to get there.
Thank you notes
Thanks to: Paul Graham, Packy McCormick, and the Technology Brothers for the inspiration to write and publish this article; and you for reading.
Use of AI
I haven’t used AI to either write or edit this article. I am not against it, but I just prefer to use this opportunity to improve the way I think and write.